


新闻中心
联系我们
Contact us
Contact us
- 总部电话010-51727811
- 客服热线400 779 6696
- 更多联系信息
数据存储配置缓存
时间:2012-11-02 09:25 来源:飞客数据恢复 作者:飞客数据恢复工程师
配置缓存
像任何其他事情一样,为了获得最优的性能,缓存内存也需要制订计划和进行配置。
如前所述,选择适合的缓存算法是最重要的。一般而言,数据库和随机访问应用可以从LRU缓存获得最大的性能效益,而对于像图形学、视频产生、数据仓库,甚至普通的文件系统这些应用,使用预先读缓存则更适合。
1.确定缓存大小
对于一个给定的子系统,目前还没有一个既简单又好的方法确定所需要的缓存大小。虽然人们总想按照子系统的总存储量选择它,但事实上,确定缓存容量还需取决太多的其他因素,如那些潜在的、但未使用过的文件数量。
但当第一次计划实现缓存时,需要知道从哪里下手。在磁盘缓存初始安装之后,有可能希望对内存量及所使用的算法进行调整。
对于带有缓存的磁盘子系统,合理的缓存量应占总存储容量的0.1%。例如,假使有50GB的存储容量,那么,缓存内存应该安排在50MB左右。假使有1TB的容量,那么,缓存应该为1GB。虽然这个缓存量可能变化(增加),但应该明白所使用的缓存算法能否正常工作,这才是改变缓存大小的根本。
还有一个更为复杂的确定缓存量的方法,即根据缓存所服务的应用使用的数据量进行估计。一般情况下,所需要的缓存量是总数据量的0.5%~1%。例如,假使一个数据库应用拥有200GB的存储量,则可能使用1~2GB的缓存内存。
多级缓存
为了使某些类型的数据和应用达到最佳工作状态,可同时使用LRU和预先读两种缓存。图中1就是这样一种配置。
像任何其他事情一样,为了获得最优的性能,缓存内存也需要制订计划和进行配置。
如前所述,选择适合的缓存算法是最重要的。一般而言,数据库和随机访问应用可以从LRU缓存获得最大的性能效益,而对于像图形学、视频产生、数据仓库,甚至普通的文件系统这些应用,使用预先读缓存则更适合。
1.确定缓存大小
对于一个给定的子系统,目前还没有一个既简单又好的方法确定所需要的缓存大小。虽然人们总想按照子系统的总存储量选择它,但事实上,确定缓存容量还需取决太多的其他因素,如那些潜在的、但未使用过的文件数量。
但当第一次计划实现缓存时,需要知道从哪里下手。在磁盘缓存初始安装之后,有可能希望对内存量及所使用的算法进行调整。
对于带有缓存的磁盘子系统,合理的缓存量应占总存储容量的0.1%。例如,假使有50GB的存储容量,那么,缓存内存应该安排在50MB左右。假使有1TB的容量,那么,缓存应该为1GB。虽然这个缓存量可能变化(增加),但应该明白所使用的缓存算法能否正常工作,这才是改变缓存大小的根本。
还有一个更为复杂的确定缓存量的方法,即根据缓存所服务的应用使用的数据量进行估计。一般情况下,所需要的缓存量是总数据量的0.5%~1%。例如,假使一个数据库应用拥有200GB的存储量,则可能使用1~2GB的缓存内存。
多级缓存
为了使某些类型的数据和应用达到最佳工作状态,可同时使用LRU和预先读两种缓存。图中1就是这样一种配置。
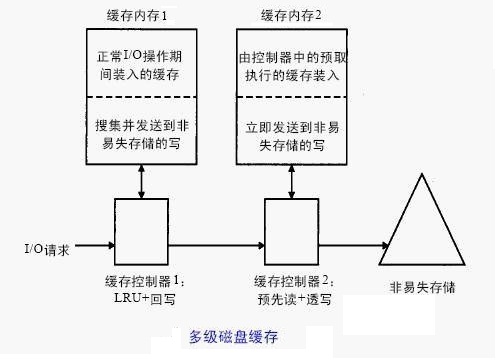
多级缓存已经有几个成功地实现方案。理解多级缓存的关键在于两方面的问题,其一是被传回到非易失存储的写的方式,其二是每个缓存加在系统和存储网络的I/O传输量的影响。
一般而言,这些缓存应该在I/O路径上串行连接,因为并行方式的缓存将产生连贯性问题,这需要专门的硬件和软件来解决。缓存连贯性问题是今天存储工业界所面临的很困难的问题。这个挑战来源于:当I/O路径正处于很忙状态时,还需要建立同步缓存内容的通信机制。对于某些特别的数据“块”,两个连续的读请求实际上接受同样的数据。当实现多级缓存时,应服从某些一般的规则:
应将I/O路径上负担最小的缓存组件放在靠近CPU的地方,通常LRU缓存与CPU最靠近。即I/O路径上负担最重的缓存组件应放在离存储子系统最近的地方。
其次,在没有后备电池保护的情况下,不要使用回写缓存。相比透写缓存来说,主机中的回写缓存将导致更好的事务处理性能。然而,为了保证在数据刷新到非易失存储后,最靠近CPU的缓存数据是可操作的,必须对I/O路径上的每个组件使用UPS保护。假如事务处理不需要回写缓存,则没有必要使用它。
一般而言,这些缓存应该在I/O路径上串行连接,因为并行方式的缓存将产生连贯性问题,这需要专门的硬件和软件来解决。缓存连贯性问题是今天存储工业界所面临的很困难的问题。这个挑战来源于:当I/O路径正处于很忙状态时,还需要建立同步缓存内容的通信机制。对于某些特别的数据“块”,两个连续的读请求实际上接受同样的数据。当实现多级缓存时,应服从某些一般的规则:
应将I/O路径上负担最小的缓存组件放在靠近CPU的地方,通常LRU缓存与CPU最靠近。即I/O路径上负担最重的缓存组件应放在离存储子系统最近的地方。
其次,在没有后备电池保护的情况下,不要使用回写缓存。相比透写缓存来说,主机中的回写缓存将导致更好的事务处理性能。然而,为了保证在数据刷新到非易失存储后,最靠近CPU的缓存数据是可操作的,必须对I/O路径上的每个组件使用UPS保护。假如事务处理不需要回写缓存,则没有必要使用它。